
命运圣契(Acmeis)使用团结引擎开发,后者是Unity中国基于Unity 2022 LTS版本针对中国市场特别开发的Unity的分支引擎,版本号形如2022.3.2t13。
美术资产解包
团结引擎与相同年份编号的Unity在BundleFile层似乎没什么区别,但是对于Texture2D之类的asset类型,可能是因为不像Unity有兼容包袱之类的,相同年份版本号下的团结引擎的资产对象的结构会更像高版本的Unity,部分类型比如AnimationClip有较大改动。
命运圣契的资产是FakeHeader加密,使用常见的AssetStudio分支可以打开文件,但是对于团结引擎修改过文件结构的类型(比如Texture2D、Mesh)会无法正常加载。截止本文撰写时间,我所知的支持读取团结引擎资产的工具只有如下两个:AssetStudio_Tuanjie和我自己维护的Razmoth版本的分支
UnityPy之后可能也会支持团结引擎,AssetRipper我不熟悉就不太清楚了。
LuaJit
在安装包的assets\Android\script路径下可以看到csharp和lua文件,因为游戏混合使用XLua和HybridCLR进行热更新。
导出lua脚本可以发现使用的是luajit,这里使用这个版本的ljd进行反编译,但是提示

很明显是读取prototype的时候结构有问题,合理怀疑游戏魔改了prototype结构,可以对照xlua中luajit部分的源码和反编译部分
xlua中读取luajit的prototype的函数在lj_bcread.c文件中,代码如下
/* Read a prototype. */
GCproto *lj_bcread_proto(LexState *ls)
{
GCproto *pt;
MSize framesize, numparams, flags, sizeuv, sizekgc, sizekn, sizebc, sizept;
MSize ofsk, ofsuv, ofsdbg;
MSize sizedbg = 0;
BCLine firstline = 0, numline = 0;
/* Read prototype header. */
flags = bcread_byte(ls);
numparams = bcread_byte(ls);
framesize = bcread_byte(ls);
sizeuv = bcread_byte(ls);
sizekgc = bcread_uleb128(ls);
sizekn = bcread_uleb128(ls);
sizebc = bcread_uleb128(ls) + 1;
if (!(bcread_flags(ls) & BCDUMP_F_STRIP)) {
sizedbg = bcread_uleb128(ls);
if (sizedbg) {
firstline = bcread_uleb128(ls);
numline = bcread_uleb128(ls);
}
}
/* Calculate total size of prototype including all colocated arrays. */
sizept = (MSize)sizeof(GCproto) +
sizebc*(MSize)sizeof(BCIns) +
sizekgc*(MSize)sizeof(GCRef);
sizept = (sizept + (MSize)sizeof(TValue)-1) & ~((MSize)sizeof(TValue)-1);
ofsk = sizept; sizept += sizekn*(MSize)sizeof(TValue);
ofsuv = sizept; sizept += ((sizeuv+1)&~1)*2;
ofsdbg = sizept; sizept += sizedbg;
/* Allocate prototype object and initialize its fields. */
pt = (GCproto *)lj_mem_newgco(ls->L, (MSize)sizept);
pt->gct = ~LJ_TPROTO;
pt->numparams = (uint8_t)numparams;
pt->framesize = (uint8_t)framesize;
pt->sizebc = sizebc;
setmref(pt->k, (char *)pt + ofsk);
setmref(pt->uv, (char *)pt + ofsuv);
pt->sizekgc = 0; /* Set to zero until fully initialized. */
pt->sizekn = sizekn;
pt->sizept = sizept;
pt->sizeuv = (uint8_t)sizeuv;
pt->flags = (uint8_t)flags;
pt->trace = 0;
setgcref(pt->chunkname, obj2gco(ls->chunkname));
/* Close potentially uninitialized gap between bc and kgc. */
*(uint32_t *)((char *)pt + ofsk - sizeof(GCRef)*(sizekgc+1)) = 0;
/* Read bytecode instructions and upvalue refs. */
bcread_bytecode(ls, pt, sizebc);
bcread_uv(ls, pt, sizeuv);
/* Read constants. */
bcread_kgc(ls, pt, sizekgc);
pt->sizekgc = sizekgc;
bcread_knum(ls, pt, sizekn);
/* Read and initialize debug info. */
pt->firstline = firstline;
pt->numline = numline;
if (sizedbg) {
MSize sizeli = (sizebc-1) << (numline < 256 ? 0 : numline < 65536 ? 1 : 2);
setmref(pt->lineinfo, (char *)pt + ofsdbg);
setmref(pt->uvinfo, (char *)pt + ofsdbg + sizeli);
bcread_dbg(ls, pt, sizedbg);
setmref(pt->varinfo, bcread_varinfo(pt));
} else {
setmref(pt->lineinfo, NULL);
setmref(pt->uvinfo, NULL);
setmref(pt->varinfo, NULL);
}
return pt;
}
在IDA中找到对应的函数
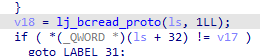

可以看出,numparams这几个byte都是做了异或处理。但是再往下看
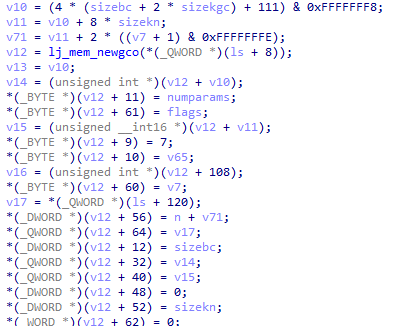
可以看出,framesize和sizeuv的顺序被调换了
回到ljd,找到prototype.py,修改其中的_read_counts_and_size函数:
def _read_counts_and_sizes(parser, prototype):
prototype.arguments_count = parser.stream.read_byte() ^ 3
# prototype.framesize = parser.stream.read_byte()
parser.upvalues_count = parser.stream.read_byte() ^ 5
prototype.framesize = parser.stream.read_byte() ^ 2
# parser.upvalues_count = parser.stream.read_byte()
parser.complex_constants_count = parser.stream.read_uleb128()
parser.numeric_constants_count = parser.stream.read_uleb128()
parser.instructions_count = parser.stream.read_uleb128()
然后就能正确的反编译了
Comments 7 条评论
反编译后才能用studio提取资源吧?大佬 网易的绝对演绎能解吗
@呆_味 不理解你想问什么
@轩晞宇·AXiX 前面的没问清楚,不过已经解决了。 网易的 绝对演绎 能支持解吗?
@呆_味 没兴趣,没时间
@轩晞宇·AXiX 没关系,不用麻烦了,找到方法了,3Q
大佬好, 针对于luajit的逆向, 似乎可以使用如下工具来替代ljd完成更好的逆向?
不过luajit似乎无论如何都会丢掉部分inline var name, 这点还是不如luac和明文lua舒服,也算是增加了一些微小的分析难度.
https://github.com/marsinator358/luajit-decompiler-v2
@0xAA 正好这两天又研究的游戏也是luajit,感谢你的推荐,我会试试看的