
昨天星落开放了预下载,可以提前下载资源,注意到在所有资源下载完成之后,又更新了几次6M左右的文件,合理推测是游戏的Lua脚本文件。
65b7b25ae5b0db3233364259a98109bd.bundle和d12a1efcaf91222406270a545c6ea088.bundle这两个文件就是被频繁更新的两个包含lua脚本的ab包(关于解包和修改部分参考我在另一个地方的帖子,这里就不赘述了)
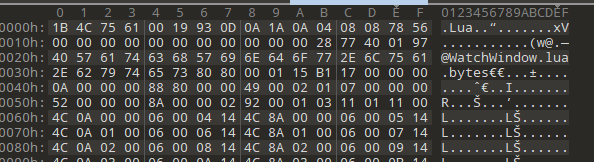
一眼顶真,鉴定为luac,但是lua版本被抹去了,试试之前写的对XLua 5.3版本的反编译脚本
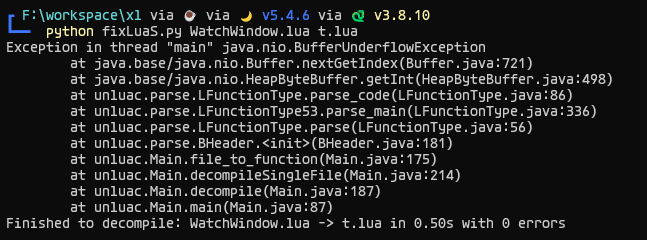
看起来头部数据段有问题,把libxlua.so丢进IDA看看

ok,666。谁家好人lua版本是666啊。那只能看看OpCode来确认lua版本了
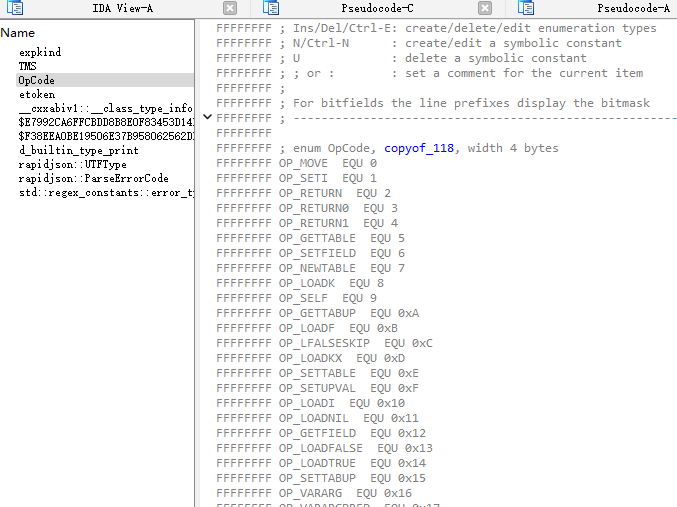
看到OP_SETI就很明显,应该是lua5.4,对比一下lua5.4编译的luac文件头,修复一下
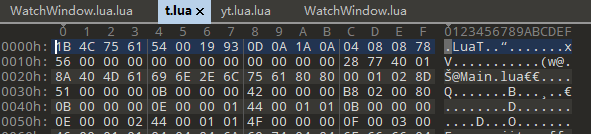
但是注意到,这个so文件中的OpCode数量是118而且顺序也和官方的不一样,所以我们得把这个enum导出一个opmap供unluac使用
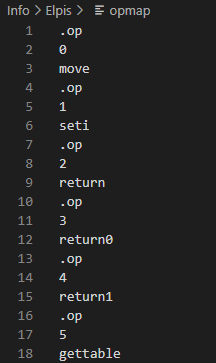
写出解密脚本
import os
import shutil
import subprocess
import sys
import time
FIXED_HEAD = (b'\x1B\x4C\x75\x61\x54\x00\x19\x93\x0D\x0A\x1A\x0A\x04\x08\x08\x78'
b'\x56\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x28\x77\x40\x01')
unluac_path = "unluac.jar"
opmap_path = "opmap"
def fixFile(src: str, dst: str):
'''
修复luac文件的文件头
'''
with open(src, 'rb') as f:
data = f.read()
end = data.find(b'\x28\x77\x40\x01')
if end == -1:
global error_msg
error_msg.append(f'Invalid luac file: {src}')
global invalid_files
invalid_files.append(src)
return
HEAD_LEN = end + 4
data = FIXED_HEAD + data[HEAD_LEN:]
filename, _ = os.path.splitext(dst)
dst = filename + '.lua'
with open(dst, 'wb') as f:
f.write(data)
def fixDir(src: str, dst: str):
files = os.walk(src)
tmp_files = []
for root, _, filenames in files:
for filename in filenames:
src_file = os.path.join(root, filename)
relative_path = os.path.relpath(src_file, src)
dst_file = os.path.join(dst, relative_path)
dst_dir = os.path.dirname(dst_file)
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
fixFile(src_file, dst_file)
def decompile(src: str, dst: str) -> bool:
'''
使用unluac.jar解密luac文件
'''
command = f'java -jar {unluac_path} {src} -o {dst} --opmap {opmap_path}'
result = subprocess.run(command, shell=True)
if result.returncode == 0:
return True
else:
return False
def handle_invalid_files(src: str, dst: str):
global invalid_files
for file in invalid_files:
shutil.copy(file, file.replace(src, dst))
if __name__ == '__main__':
start_time = time.time()
global error_msg
error_msg = []
global invalid_files
invalid_files = []
src = sys.argv[1]
dst = sys.argv[2]
if os.path.isfile(src):
fixFile(src, f'{src}.tmp')
decompile(f'{src}.tmp', dst)
os.remove(f'{src}.tmp')
else:
os.makedirs(f'{src}_tmp')
fixDir(src, f'{src}_tmp')
decompile(f'{src}_tmp', dst)
os.system(f'rm -rf {src}_tmp')
handle_invalid_files(src, dst)
end_time = time.time()
print(f'Finished to decompile: {src} -> {dst} in {end_time - start_time:.2f}s with {len(error_msg)} errors')
for msg in error_msg:
print(msg)
对于luac反编译的lua代码,其中的中文字符是utf8的编码,可以使用另一个脚本来转换
import re
import os
def tran(input_path, output_path):
pattern = re.compile(r'(\\(\d{3}))+')
with open(input_path, 'r', encoding='utf-8') as input_file:
content = input_file.read()
def replace_long_match(match):
codes = match.group().split('\\')[1:]
byte_values = [int(code) for code in codes]
byte_sequence = bytes(byte_values)
result = ""
try:
result = byte_sequence.decode('utf-8')
except UnicodeDecodeError:
result = match.group()
return result
content = pattern.sub(replace_long_match, content)
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.write(content)
if __name__ == '__main__':
import sys
if len(sys.argv) < 2:
print("Usage: python script.py input_file <output_file>")
sys.exit(1)
input_path = sys.argv[1]
if os.path.isfile(input_path):
tran(input_path, input_path)
else:
files = os.walk(input_path)
for path, _, file_list in files:
for file_name in file_list:
file_path = os.path.join(path, file_name)
tran(file_path, file_path)
上面使用的unluac.jar是我修改过的支持输入输出文件夹的,不然遍历文件执行java -jar unluac.jar的启动时间太浪费了,仓库在这里unluac
Comments 5 条评论
学习了
学习了
不过解密脚本中的第29行是不是有错误
dst = filename + ‘.lua’ 应改为 dst = filename + ‘.tmp’
那个导出的opmap可以分享一下吗,我自己捣腾了半天也没找到T_T
@2609113802 https://github.com/AXiX-official/UnityAnimeGamesInfo/blob/main/Info/Elpis/Elpis.md
@轩晞宇·AXiX 感谢